
Fields
Evolutionary Robotics
Evolutionary Computation: Genetic Algorithm, Evolutionary Strategy, Genetic Programming, etc.
Deep Learning: CNN, RNN, Reinforcement Learning, etc.
2D/3D Physics Engine
Python, C/C++, CUDA
About
I am currently a graduate student at University of Vermont. My program is called Masters in Complex Systems and Data Science. My advisor is Josh Bongard, and in the Morphology, Evolution & Cognition Laboratory, I mainly work with Sam Kriegman on evolutionary robotic research projects.
Broadly speaking, I am interested in how complex systems work, for example, how does intelligence work, or how does life work. My approach of studying such systems is by modeling them, using computer programs.
There are two kinds of problem in general that I need to study. The first one is that we have input and model, and by simulating the whole process, we get the output. The simulation I made is belong to this category, and the extreme case is the Wolfram Physics Project. The second one is that we have output, and using optimization, we search for the input or model. Evolutionary Algorithm and Deep Learning are both belong to this category.
Before I came to the US, I was a vendor of bags and belts. My partners and I ran a online store which is the official online store of Tucano (one of the leading leather brands in China).
Projects
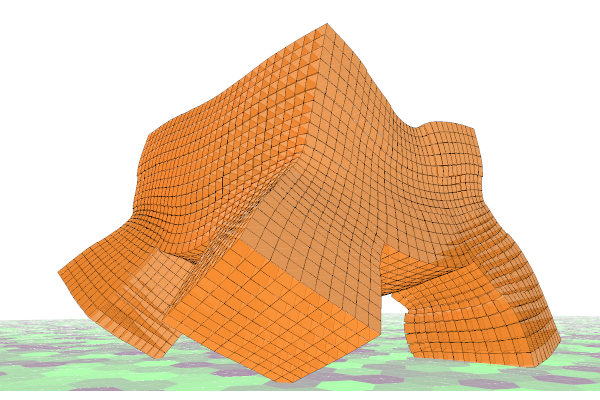
gpuVoxels
A voxel-based physics simulation for evolutionary robotics implemented in CUDA
https://github.com/liusida/gpuVoxels/
I noticed that researchers were using a voxel-based simulation Voxelyze that runs on CPU, so I studied it and rewrote it so that it can run on multiple GPUs. Also I added some new features in the gpuVoxels to support new experiments.
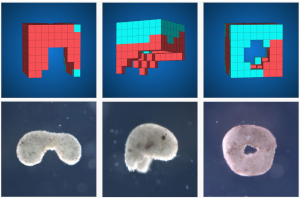
Xenobots
Xenobots are automatically designed by computers to perform some desired function and built by combining together different biological tissues
I just joined this project, and let's see what I can contribute.

Voxcraft
Using hollow silicone blocks to make soft robots
I just joined this project, and let's see what I can contribute.
Education
University of Vermont
Master of Science in Complex Systems
2019-2021
Morphology, Evolution & Cognition Laboratory